제어문
control statement
제어문
일반적으로 코드는 위에서 아래로 순차적으로 실행되는데, 제어문을 사용하면 주어진 조건에 따라 코드 블록을 실행하거나 반복실행 하여 코드의 실행 순서를 인위적으로 제어할 수 있다.
조건문
if문
-
기본 구조
if (조건식) { // 조건식이 true 일때 수행될 문장 작성 } if (조건식) 문장; // 수행될 문장이 하나인 경우 블럭{} 생략 가능 -
if - elseif (조건식) { // 조건식이 true 일때 수행될 문장 작성 } else { // 조건식이 false 일때 수행될 문장 작성 } if (조건식) 문장; else 문장; -
if-else ifif (조건식1) { // 조건식1의 연산결과가 true일 때 수행될 문장 작성 } else if (조건식2) { // 조건식2의 연산결과가 true일때 수행될 문장 작성 // 여러개의 else-if 사용 가능 } else { // 위의 어느 조건식도 만족하지 않을 때 수행될 문장 작성 // 생략 가능 } -
중첩 if문
if (조건식1) { // 조건식 1의 연산결과가 true일때 수행될 문장 작성 if (조건식2) { // 조건식1과 2 모두 true일 때 수행될 문장 작성 } else { // 조건식1이 true이고 2가 false 일떄 수행될 문장 작성 } } else { // 조건식1이 false일때 수행될 문장 작성 }if 문 블럭 내에 또 다른 if문을 사용하는 것을 중첩 if문이라 한다. 중첩의 횟수에는 거의 제한이 없으나 너무 많이 사용하면 가독성이 떨어진다.
switch 문
조건의 경우의 수가 많을 때는 if문보다 switch문을 사용하면 더 간결하고 알아보기 쉽다.
또, if문은조건식을 계산해야하므로 수행시간도 많이 걸리는데 switch문의 조건식은 하나의 조건식만 계산하고 그 결과에 따라 어떤 문장을 수행할지 결정하므로 if문보다 속도가 빠르다.
그러나, if문보다 제약조건이 많기 때문에 switch문은 항상 if문으로 변환 가능하지만 if문은 switch문으로 작성할 수 없는 경우가 많다.
- 기본 구조
switch (조건식) {
case 값1 :
// 조건식의 결과가 값1과 같을 경우 수행될 문장
// ...
break;
case 값2 :
// 조건식의 결과가 값2과 같을 경우 수행될 문장
// ...
break;
default :
// 조건식의 결과와 일치하는 case문이 없을 때 수행될 문장
}
switch문의 조건식은 연산결과가 int형 범위의 정수값이어야 한다. byte, short, char, int 타입의 변수나 리터럴을 사용할 수 있다.
case문에는 오로지 리터럴이나 상수만을 허용한다. (변수는 허용 x)
-
순서 : 조건식을 먼저 계산한 후 그 결과와 일치하는 case문으로 이동한다. 이동한 case문 안에 있는 문장들을 수행한 후 break문을 만나면 전체 switch문을 빠져나간다.
만일 break를 생략하면 다른 break 문을 만나거나 switch문 블럭 {} 끝을 만날때까지 나오는 모든 문장들을 수행한다.
반복문
for문
for (초기화; 조건식; 증감식) {
// 조건식이 true 일때 수행될 문장들을 적는다. (실행문)
}
-
실행순서
1. 초기화 -----> 2. 조건식 -----> 3. 수행될 문장 -----> 4. 증감식 ^ ㅣ-------------------------------------ㅣ초기화는 처음 한번만 실행 되고 그 이후부터는 조건식을 만족하는 한 2 → 3 → 4 순서로 계속 반복되다가 조건식 결과가 false가 되면 for문 전체를 빠져나가게 된다.
초기화, 조건식, 증감식은 모두 생략 가능하며 조건식이 생략되면 true로 간주된다.
for-each문
JDK 5.0부터 지원하는 식으로 기본 형식은 다음과 같다.
-
기본형식
for (변수타입 변수이름 : 배열이름) 문장; -
예시
int ages[] = {11, 21, 31, 41, 51} for (int age : ages) { System.out.println(age); }배열의 항목 수만큼 실행부분을 반복하는데 반복이 이루어질때마다 배열의 항목을 순서대로 꺼내어 변수 (age)에 자동으로 대입해준다.
단, 배열의 값을 가져다 사용할 수만 있고 수정할 수는 없다.
-
for문과 for-each문의 성능차이
- LinkedList 경우 for-each문이 빠름 (내부적으로 iterator사용)
- ArrayList 경우 for문이 살짝 더 빠름
- Array의 경우 for문이 빠름
💡 성능을 고려한다면 ArrayList와 Array는 for문 사용
💡 LinkedList는 For-each문 사용
while문
while (조건식) {
// 조건식의 연산결과가 true일때 수행될 문장들을 적는다.
}
기본식은 위와 같다. for문과 while문은 항상 서로 변환이 가능한데 카운터변수와 증감식을 함께 사용하면 for문과 동일하게 사용할 수 있다.
단, 잘못 작성하면 무한반복에 빠질 수 있으니 반복문에 카운터가 필요한 경우는 for문으로 작성하는 것이 좋다.
do-while문
while문의 변형으로, 차이점으로는 블럭 {}이 먼저 수행 한 후에 조건식을 판단한다는 것이다. while문은 조건식의 결과에 따라 블럭{}이 한번도 수행되지 않을 수 있지만 do-while문은 최소한 한번은 수행될 것을 보장한다.
do {
// 조건식의 연산결과가 true일 때 수행될 문장
} while (조건식);
break문
현재 위치에서 가장 가까운 switch문 또는 반복문을 벗어나는데 사용된다.
주로 if문과 함께 사용되어 특정 조건을 만족하면 벗어나도록 한다.
int sum = 0;
int i = 0;
while(true) {
if (sum > 100)
break; // sum이 100이상이면 while문을 벗어난다.
i++;
sum +=i
}
continue 문
반복문내에서만 사용할 수 있으며 반복이 진행되는 도중에 continue문을 만나면 반복문의 끝으로 이동하여 다음 반복으로 넘어간다.
- for문의 경우 증감식으로 이동
- while문, do-while문의 경우 조건식으로 이동
반복문 전체를 벗어나지 않고 다음 반복을 계속 수행한다는 점에서 break문과 다르다.
for (int i=0; i <=10; i++) {
if (i % 3 == 0)
continue;
System.out.println(i);
}
반복문에 이름 부여하기 (Label)
여러 반복문이 중첩되어 있을 때 반복문 앞에 이름을 붙이고 break문이나 continue문에 반복문의 이름을 지정해주면 하나 이상의 반복문을 벗어나거나 건너뛸 수 있다.
Loop1: for (int i = 3; i <= 9; i++) {
for (int j = 1; j <= 9; j++) {
if (j == 5) {
break Loop1;
}
System.out.println(i + "*" + j + "=" + i * j);
}
}
// 결과
// 3*1=3
// 3*2=6
// 3*3=9
// 3*4=12
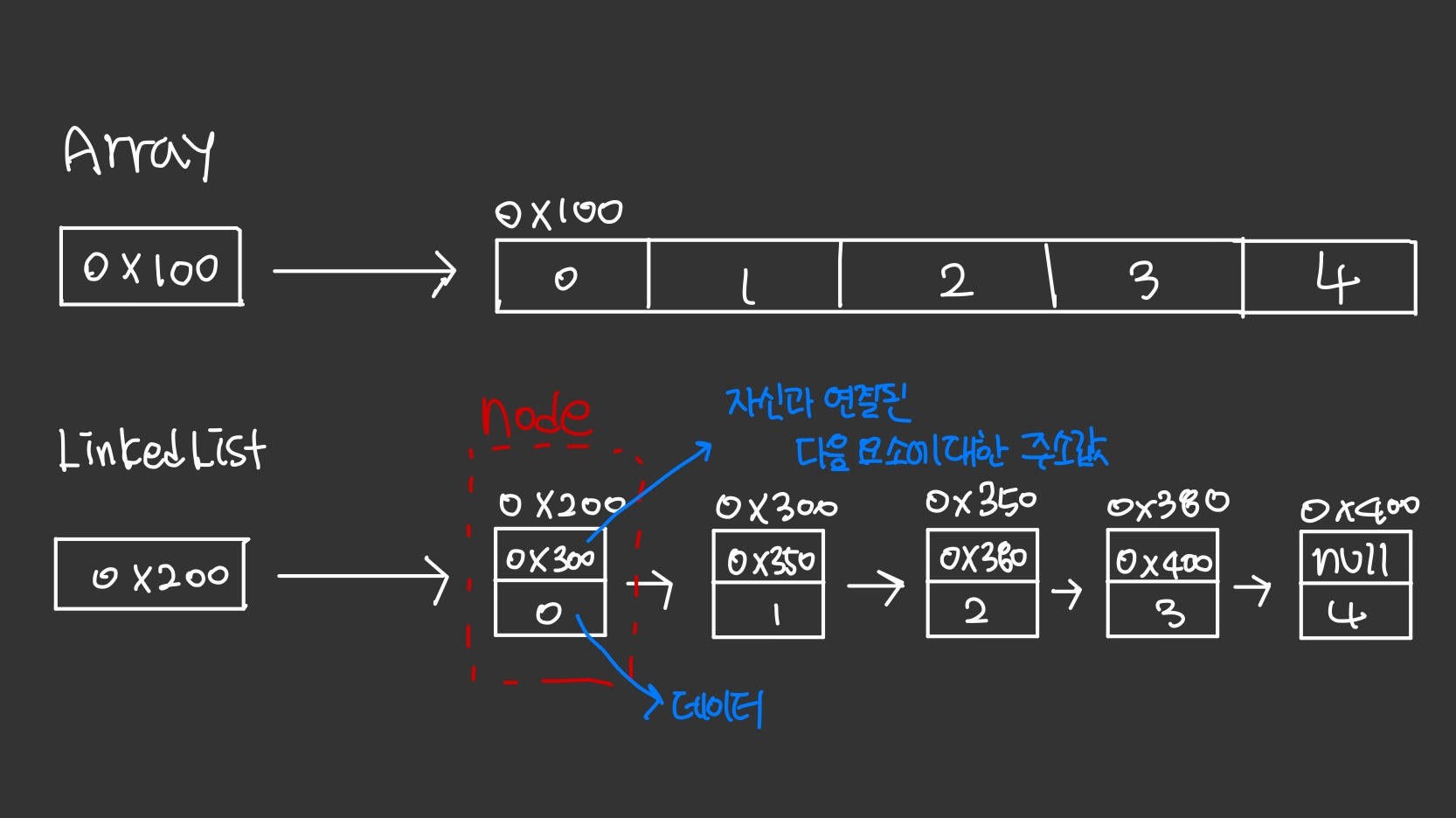
LinkedList
배열의 단점을 보완하기 위해서 나온 자료구조로 불연속적으로 존재하는 데이터를 서로 연결(Link)한 형태로 구성되어 있다.
- 배열의 단점
- 크기를 변경할 수 없다.
- 크기를 변경할 수 없기때문에 새로운 배열을 생성해서 데이터를 복사하는 작업이 필요
- 실행속도를 향상시키기 위해서는 큰 크기의 배열을 생성해야 하므로 메모리가 낭비된다.
- 비순차적인 데이터 추가 또는 삭제에 시간이 많이 걸린다.
- 차례대로 데이터를 추가하고 마지막에서부터 데이터를 삭제하는 과정은 빠름
- 단, 배열의 중간에 데이터를 추가하려면, 빈자리를 만들기 위해 다른 데이터를 복사해서 이동해야 함 (시간이 많이 걸림)
- 크기를 변경할 수 없다.
중간에 데이터를 추가 또는 삭제하더라도 전체의 인덱스가 한 칸씩 뒤로 밀리거나 당겨지는 일이 없기에 추가나 삭제가 용이하나, 인덱스가 없기에 특정 요소에 접근하기 위해서는 순차 탐색이 필요하여 탐색 속도가 떨어진다.
💡 순차적으로 추가 / 삭제 하는 경우에는 ArrayList가 LinkedList 보다 빠르다.
💡 중간 데이터를 추가 / 삭제 하는경우에는 LinkedList가 ArrayList 보다 빠르다.
구조
삭제 / 추가
-
삭제
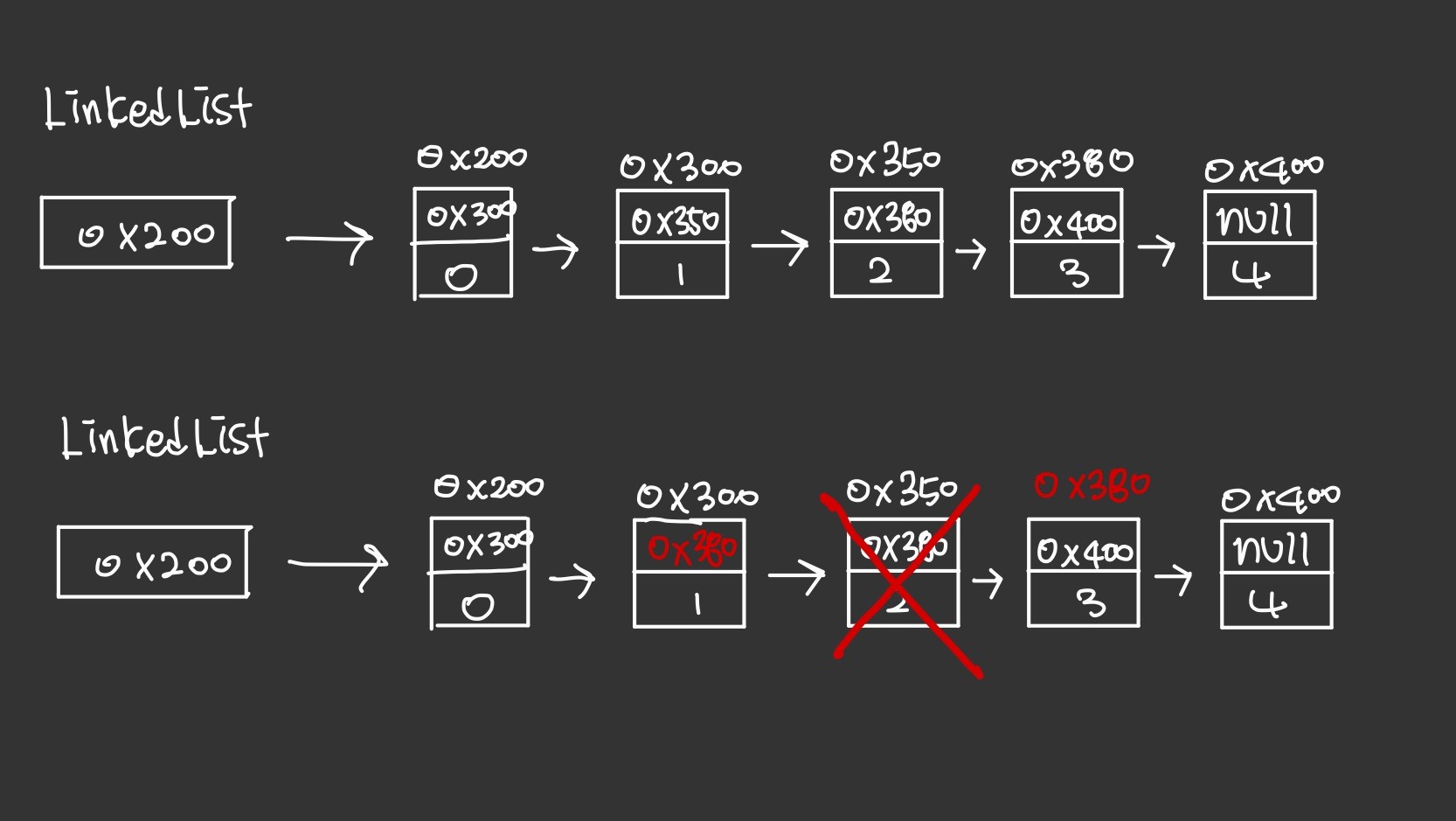
삭제하고자 하는 요소의 이전요소가 삭제하고자 하는 요소의 다음요소를 참조하도록 변경만 하면 되서 간단하다. 배열처럼 데이터를 이동하기 위해 복사하는 과정이 없기 때문에 처리속도가 매우 빠르다.
-
추가
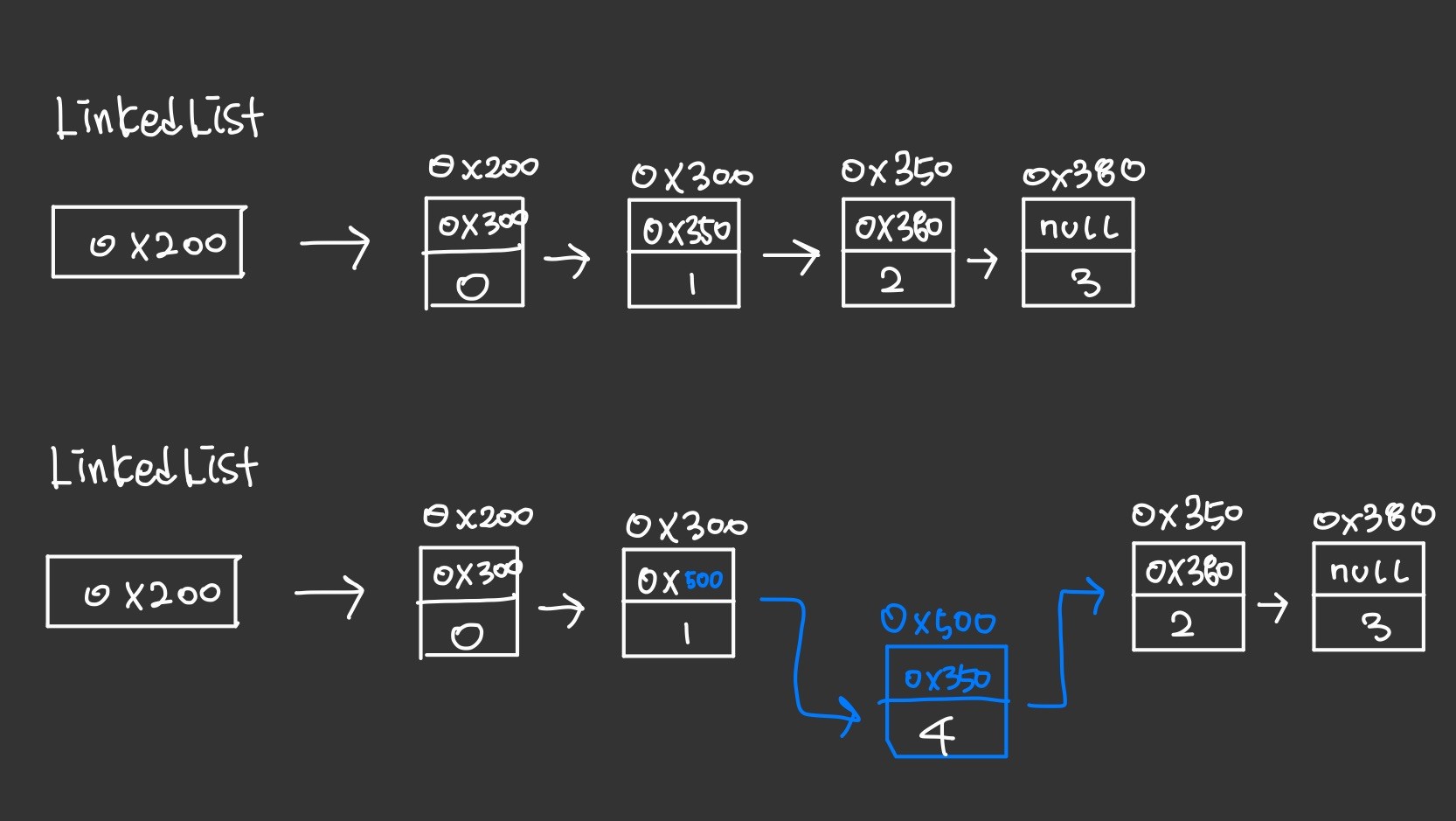
추가시에는 새로운 요소를 생성한 다음 추가하고자 하는 위치의 이전 요소의 참조를 새로운 요소의 참조로 변경해주고 새로운 요소가 그 다음 요소로 참조하도록 변경해주면 끝이므로 처리속도가 매우 빠르다.
사용법
-
선언
LinkedList list = new LinkedList(); LinkedList<Students> students = new LinkedList<Student>(); LinkedList<Integer> ages = new LinkedList<Integer>(); LinkedList<Integer> bookCount = new LinkedList<>(); LinkedList<Integer> coffeeCount = new LinkedList<Integer>(Arrays.asList(3,4)); -
값 추가
LinkedList<Integer> ages = new LinkedList<Integer>(); ages.addFirst(10); // 맨 앞에 데이터 추가 ages.addLast(50); // 맨 뒤에 데이터 추가 ages.add(25); // 중간에 데이터 추가 ages.add(1, 31); // index 1 뒤에 데이터 추가 -
값 삭제
LinkedList<Integer> ages = new LinkedList<Integer>(); ages.removeFirst(10); // 맨 앞에 데이터 삭제 ages.removeLast(50); // 맨 뒤에 데이터 삭제 ages.remove(1); // index 1인 데이터 삭제 ages.remove(); // index 0인 데이터 삭제 ages.clear(); // 모든 값 삭제 -
크기
LinkedList<Integer> ages = new LinkedList<Integer>(); System.out.prinltn(ages.size()); -
값 검색
LinkedList<Integer> ages = new LinkedList<Integer>(); System.out.println(ages.contains(25)) // ages에 25이 있는지 검색함. 결과값은 boolean System.out.println(ages.indexOf(25)) // 25이 있는 index 반환 없으면 -1
| 컬렉션 | 읽기 (접근시간) | 추가/삭제 | 비고 |
|---|---|---|---|
| ArrayList | 빠르다 | 느리다 | 순간적인 추가 삭제는 빠름, 비효율적인 메모리 사용 |
| LinkedList | 느리다 | 빠르다 | 데이터가 많을수록 접근성이 떨어짐 |
Doubly Linked list
링크드리스트는 이동방향이 단방향이기 때문에 이전요소에 대한 접근이 어렵다. 이 점을 보완한것이 더블링크드리스트이다.
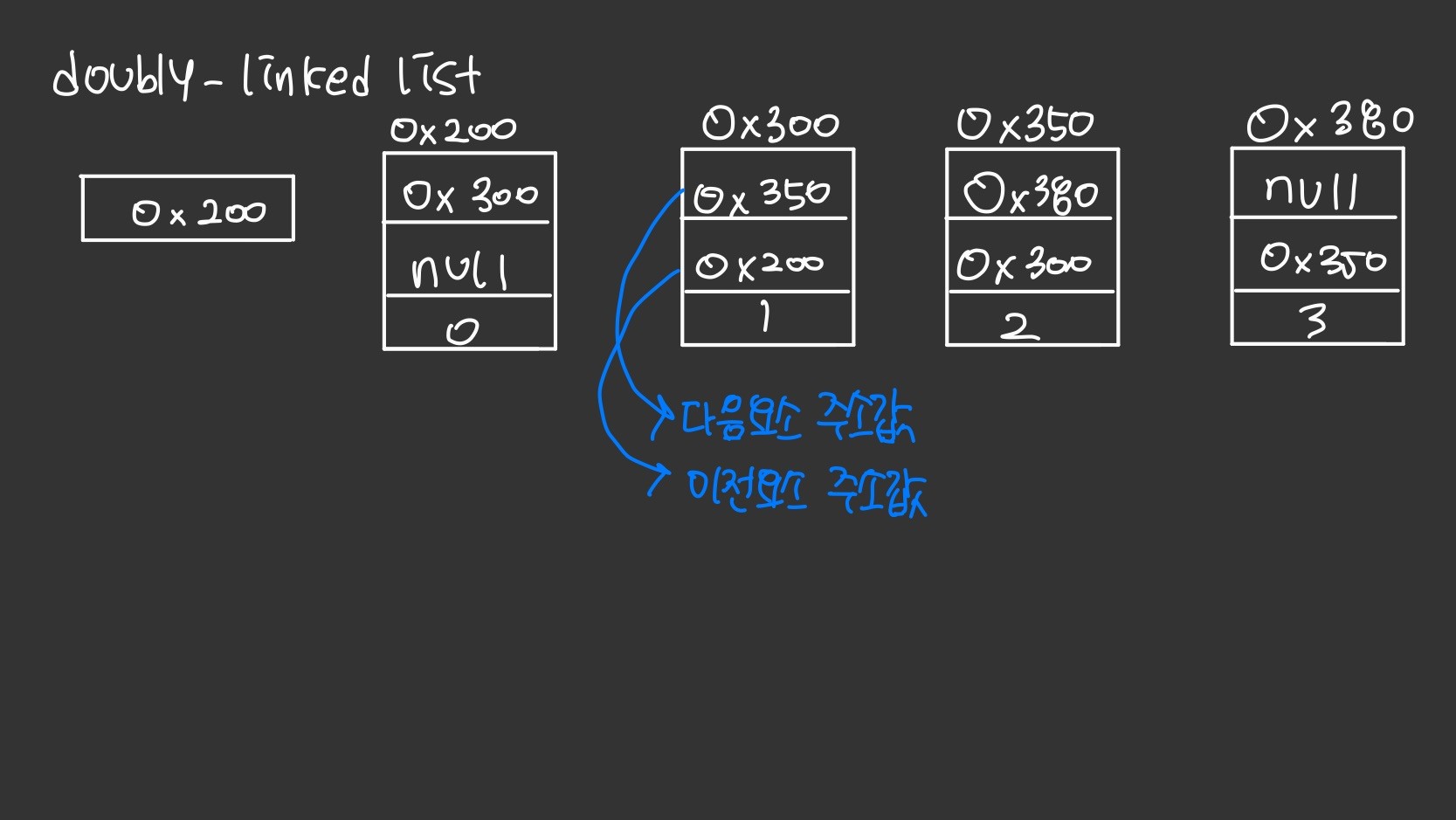
단순히 링크드리스트에 이전요소 참조변수를 하나 더 추가한것 뿐 그 외는 링크드리스트와 같다.
LinkedList
- LinkedList
public class LinkedList {
private Node head; // 누가 첫 번째 노드인가?
private Node tail; // 누가 끝에 있는 노드인가?
private int size; // 몇개의 element 가 포함되어 있는가 (1 element = 1 object = 1 node)
/*
하나의 노드를 생성하기 위해서는 데이터(data), 다음노드가 누구인지에 대한 정보(next)를 저장해야함.
*/
private static class Node {
private int data; // 데이터 저장 변수
public Node next; // 누가 다음 노드인가를 저장하는 변수
// 다음 노드도 노드이기 때문에 Node 타입으로 생성
public Node(int inputData) {
this.data = inputData;
this.next = null; // 생성자로 만들어질 때 누가 다음노드인지 알 수 없기 때문에 null 로 초기화
}
}
}
-
첫 번째 노드로 삽입
public void addFirst(int input) { Node newNode = new Node(input); // 새로운 객체(=요소) 생성 (data : input, next : null) newNode.next = head; // 다음 노드에 대한 정보를 저장 /* head 에 만든 요소(NewNode)를 저장하는 이유는 다음 노드 만들 때 그 노드의 next 에 이전 요소를 참조해야 LinkedList 의 첫 번째 요소로 올 수 있기 때문이다. */ head = newNode; // 노드를 추가했기 때문에 size 를 1 증가시킨다. size++; // node 가 1개 있는 상황이라면 하나의 노드가 리스트의 첫번째(head) 이면서 마지막(tail)이기도 하다는 의미 // 그러므로 head 와 tail 이 지금 만든 (첫번째, 하나의 노드) 를 가르키게 해야 함. if (head.next == null) { // 다음 노드가 없다 tail = head; } } -
마지막 노드로 삽입
public void addLast(int input) { Node newNode = new Node(input); // 새로운 객체 생성 if (size == 0) { addFirst(input); // 리스트에 노드가 없다 -> 첫번째 노드 추가 하자 } else { tail.next = newNode; // 끝에 있는 노드가 새로운 노드를 바라본다면 새로운 노드가 제일 끝에 추가 되는 것 tail = newNode; // 끝에있는 노드는 새로운 노드가 된다. size++; } } -
중간 노드 삽입
// 원하는 위치에 끼워 넣는 메소드 public void add(int k, int input) { if (k == 0) { addFirst(input); } else { // 이전노드가 참조하는 값을 새롭게 만든 노드(newNode)로 변경하고 새로운 요소의 next를 이전 노드의 next로 변경해주면 됨 Node temp1 = node(k - 1); // 이전 노드 Node temp2 = temp1.next; // 들어갈 요소의 다음 노드 Node newNode = new Node(input); temp1.next = newNode; newNode.next = temp2; size++; if (newNode.next == null) { tail = newNode; } } } -
첫 번째 노드 삭제
public int removeFirst() { Node temp = head; head = head.next; int removeData = temp.data; temp = null; size --; return removeData; // 삭제한 데이터 }temp 변수에 첫번째 노드 값 저장하고 head의 값을 두번째 노드로 변경하면 삭제할 준비가 완료
-
중간 노드 삭제
public int remove(int k) { if (k == 0) { return removeFirst(); // 삭제 하는 값이 첫 번째 노드일때 } else { // 삭제를 하기 위해서는 이전 노드를 알아야함. (삭제될 노드의 이전 노드의 next를 바꿔줘야 하기 때문에) Node temp = node(k - 1); // 이전 노드 Node deletedNode = temp.next; // 삭제할 노드 temp.next = temp.next.next; int returnDeleteData =deletedNode.data; if (deletedNode == tail) { tail = temp; } deletedNode = null; size --; return returnDeleteData; } } -
마지막 노드 삭제
public int removeLast() { return remove(size -1); } -
값으로 index 찾기
public int indexOf(int data) { Node temp = head; int index = 0; // 원하는 데이터가 나올때까지 탐색 while (temp.data != data) { temp = temp.next; index ++; if (temp == null) { // 가장 마지막 노드 return -1; } } return index; }
public class ListNode {
public int value;
public ListNode next;
public ListNode(int value) {
this.value = value;
this.next = null;
}
public ListNode() {
}
public ListNode getNext() {
return next;
}
public ListNode get(ListNode head, int position) {
if (position <= 0) {
return null;
}
ListNode current = head;
while (position -- > 0) {
current = current.getNext();
if (current == null && position > 0) {
System.out.println("Out of range");
return null;
}
}
return current;
}
public ListNode add(ListNode head, ListNode nodeToAdd, int position) {
ListNode node = head;
for (int i=0; i < position -1; i++) {
node = node.next;
}
nodeToAdd.next = node.next;
node.next = nodeToAdd;
return head;
}
public ListNode remove(ListNode head, int positionToRemove) {
ListNode node = head;
if (positionToRemove == 0) {
ListNode deleteToNode = node;
head = node.next;
deleteToNode.next = null;
return deleteToNode;
}
for (int i=0; i < positionToRemove -1; i++) {
node = node.next;
}
ListNode deleteToNode = node.next;
node.next = deleteToNode.next;
deleteToNode.next = null;
return deleteToNode;
}
public boolean contains(ListNode head, ListNode hasNode) {
while (head.next != null) {
if (head.next == hasNode) {
return true;
}
head = head.next;
}
return false;
}
}
public class LinkedListTest {
private ListNode listNode;
private static final int[] ADD_NUMBERS = {3, 5, 100, 7, 9, 11};
public static final boolean[] CONTAINS_NUMBERS = {true, false};
public static List<Integer> acc_numbers;
@BeforeEach
void setListNode() {
acc_numbers = new ArrayList<>();
listNode = new ListNode();
ListNode firstNode = new ListNode(3);
ListNode secondNode = new ListNode(5);
ListNode thirdNode = new ListNode(7);
ListNode fourthNode = new ListNode(9);
ListNode fifthNode = new ListNode(11);
this.listNode = firstNode;
firstNode.next = secondNode;
secondNode.next = thirdNode;
thirdNode.next = fourthNode;
fourthNode.next = fifthNode;
}
@Test
void add() {
listNode = listNode.add(listNode, new ListNode(100), 2);
while (listNode != null) {
acc_numbers.add(listNode.value);
listNode = listNode.next;
}
for (int i = 0; i < acc_numbers.size(); i++) {
Assertions.assertEquals(ADD_NUMBERS[i], acc_numbers.get(i));
}
}
@Test
void remove() {
ListNode removed = listNode.remove(listNode, 3);
Assertions.assertEquals(9, removed.value);
}
@Test
void contains() {
boolean[] result = new boolean[2];
result[0] = listNode.contains(listNode, new ListNode(9));
result[1] = listNode.contains(listNode, new ListNode(100));
for (int i = 0; i < acc_numbers.size(); i++) {
Assertions.assertEquals(CONTAINS_NUMBERS[i], result[i]);
}
}
}
스택(Stack) / 큐 (Queue)
스택은 마지막에 저장한 데이터를 가장 먼저 꺼내게 되는 LIFO(Last In First Out) 구조이다.
큐는 처음에 저장한 데이터를 가장 먼저 꺼내게 되는 FIFO(First In First Out) 구조이다.
순차적으로 데이터를 추가하고 삭제하는 스택에는 ArryaList 와 같은 배열기반의 컬렉션 클래스가 적합하지만 큐는 데이터를 꺼낼 때 항상 첫 번째 저장된 데이터를 삭제하므로 배열기반의 컬렉션 클래스를 사용한다면 데이터를 꺼낼 때마다 빈 공간을 채우기 위해 데이터의 복사가 발생하므로 비효율적이다.
큐는 데이터의 추가/삭제가 쉬운 LinkedList로 구현하는 것이 더 적합하다.
- 스택
- ex : 수식계산, 수식 괄호 검사, 웹 브라우저 뒤로 / 앞으로
- 큐
- ex : 최근 사용 문서, 인쇄작업 대기목록, 버퍼 (buffer), CPU 스케쥴링
스택의 기본연산
push- 값을 스택의 맨 위에 넣음 (넣은 값은 스택의
top이 된다.) - 만약, 공간이 없다면 overflow 상태가 되며 값을 더 넣을 수 없다.
- 값을 스택의 맨 위에 넣음 (넣은 값은 스택의
pop- 맨 위 값을 스택에서 제거 (그 다음 값이
top이 된다.) - 만약, 제거할 값이 없다면 underflow 상태가 되며, 뺄 수 없다.
- 맨 위 값을 스택에서 제거 (그 다음 값이
top- 맨 위의 값 리턴
큐의 기본 연산
- 추가 (
enqueue)- 예외발생 :
add(e) - 값 리턴 :
offer(e)
- 예외발생 :
- 삭제 (dequeue)
- 예외발생:
remove() - 값 리턴 :
poll()
- 예외발생:
- 검사 (peek)
- 예외발생:
element() - 값 리턴 :
peek()
- 예외발생:
public class ArrayStack implements Stack{
int[] stack;
int top;
public ArrayStack(int size) {
stack = new int[size];
top = -1;
}
@Override
public void push(int data) {
stack[++top] = data;
}
@Override
public int pop() {
if (top == -1) {
System.out.println("Empty");
return top;
}
return stack[top--];
}
}
class StackTest {
private ArrayStack arrayStack;
public static final int[] PUSH_DATA = {10, 20, 30, 40, 50};
@BeforeEach
void setStack() {
arrayStack = new ArrayStack(5);
}
@Test
void push() {
arrayStack.push(10);
arrayStack.push(20);
arrayStack.push(30);
arrayStack.push(40);
arrayStack.push(50);
for (int i=0; i < arrayStack.stack.length; i++) {
Assertions.assertEquals(PUSH_DATA[i], arrayStack.stack[i]);
}
}
@Test
void pop() {
arrayStack.push(10);
arrayStack.push(20);
arrayStack.push(30);
arrayStack.push(40);
arrayStack.push(50);
Assertions.assertEquals(50, arrayStack.pop());
}
}
- 추가 : 앞서 만든 ListNode를 사용해서 Stack 구현
- ListNode head를 가지고 있는 ListNodeStack 클래스를 구현하세요.
- void push(int data)를 구현하세요.
- int pop()을 구현하세요.
public class ListNodeStack implements Stack{ int top; ListNode node; public ListNodeStack() { this.node = null; this.top = -1; } @Override public void push(int data) { ListNode pushNode = new ListNode(data); if (node == null) { node = new ListNode(data); top ++; } else { node = node.add(node, pushNode, ++top); } } @Override public int pop() { if (top == -1) { System.out.println("EMPTY"); return top; } return node.remove(node, top--).value; } }private ListNodeStack stack; public static final int[] PUSH_DATA = {10, 20, 30, 40, 50}; @BeforeEach void setStack() { stack = new ListNodeStack(); } @Test void push() { stack.push(10); stack.push(20); stack.push(30); stack.push(40); stack.push(50); ListNode node = stack.node; int i=0; while (node != null) { Assertions.assertEquals(PUSH_DATA[i++], node.value); node = node.next; } } @Test void pop() { stack.push(10); stack.push(20); stack.push(30); stack.push(40); stack.push(50); Assertions.assertEquals(50, stack.pop()); Assertions.assertEquals(40, stack.pop()); Assertions.assertEquals(10, stack.pop()); // fail }
Queue를 구현
- 배열을 사용
private int[] elements; private int size = 16; private final int head = 0; private int modifyCount = 0; public QueueImpl() { elements = new int[size]; } public QueueImpl(int size) { elements = new int[size]; } public boolean offer(int data) { // 해당 큐의 맨 뒤에 전달된 요소를 삽입 if (modifyCount >= size) return false; if (data < 0) return false; elements[modifyCount] = data; ++modifyCount; return true; } public int poll() { // 해당 큐 맨 앞에 있는 요소를 반환하고 해당 요소를 큐에서 제거 int res = elements[head]; int modify = 0; for (int loop = 1; loop < modifyCount; loop++) { elements[loop - 1] = elements[loop]; modify = loop; } elements[modify] = -1; modifyCount = modify; return res; } public int size() { int size = 0; for (int index : elements) { if (index == -1 || index == 0) break; ++size; } return size; } -
ListNode를 사용
private ListNode node = null; private ListNode head; public ListNodeQueue() { } public ListNodeQueue(int element) { node = new ListNode(element); head = node; } public void offer(int data) { // 해당 큐의 맨 뒤에 전달된 요소를 삽입 if (node == null) { node = new ListNode(data); head = node; } else { ListNode nextNode = node; while (nextNode.next != null) { nextNode = nextNode.next; } nextNode.next = new ListNode(data); } } public int poll() { // 해당 큐 맨 앞에 있는 요소를 반환하고 해당 요소를 큐에서 제거 int result = head.value; ListNode nextNode = head.next; head = null; head = nextNode; return result; } public int size() { int size = 0; ListNode nextNode = head; while (nextNode != null) { ++size; nextNode = nextNode.next; } return size; }